Generative Adversarial Networks (GAN) - Basics
What is GAN?
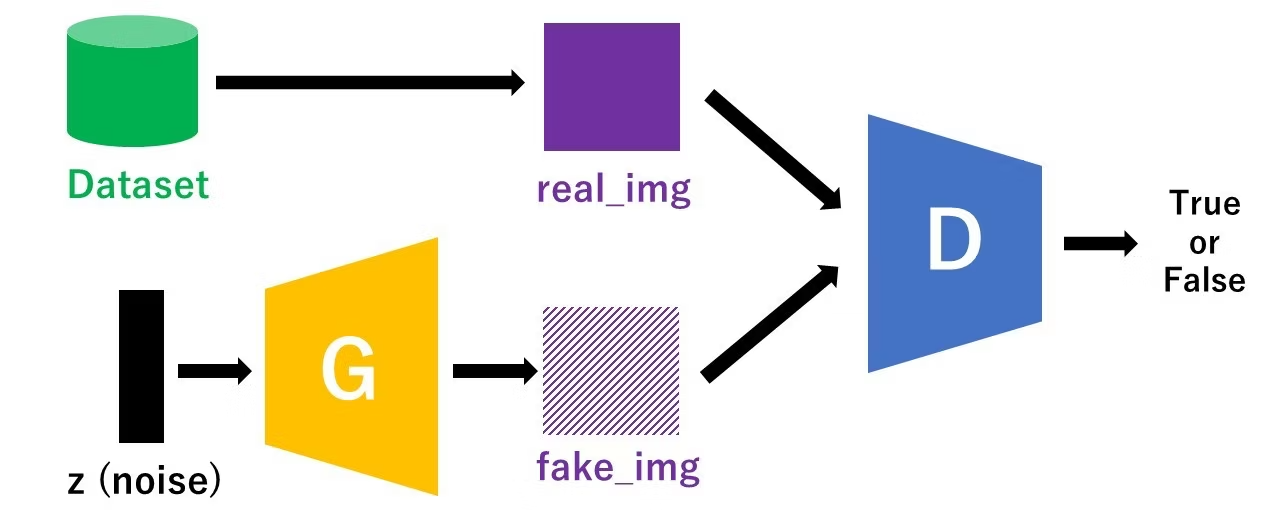
- GAN (Generative Adversarial Network) is a type of neural network that can generate new images. Unlike normal neural networks that classify or predict, GANs create something new.
GAN consists of two neural networks that compete against each other:
Generator - The "artist" that creates fake images
Discriminator - The "critic" that judges if an image is real or fake
Think of it like a game:
- The Generator tries to create images good enough to fool the Discriminator
- The Discriminator tries to get better at catching fakes
- As they compete, both improve - and the Generator learns to create realistic images.
Example: MNIST Handwritten Digits
- A classic example of GAN is generating handwritten digit images. The MNIST dataset contains 60,000 images of handwritten digits (0-9).

How it works:
- The Generator starts with random noise (meaningless numbers)
- It transforms the noise into a 28x28 pixel image
- The Discriminator compares it with real MNIST images
- Based on feedback, the Generator improves
- After training, the Generator can create realistic digit images from any random input.
Activation Functions
| Function | What it does | Used in |
|---|---|---|
| ReLU | Outputs 0 for negative, keeps positive | Generator |
| LeakyReLU | Like ReLU but allows small negatives | Discriminator |
| Tanh | Squashes output to [-1, 1] | Generator's final layer |
Why These Choices?
- Tanh for Generator output: MNIST images are normalized to [-1, 1], so Generator must output the same range
- LeakyReLU for Discriminator: Prevents "dead neurons" and helps gradients flow better
- Adam optimizer: Adapts learning rate automatically, works well for GANs
- BCEWithLogitsLoss: Binary Cross Entropy loss for real/fake classification
GAN Training Overview
- Training a GAN involves alternating between two steps:
1. Train Discriminator
- Show real images → should output "real" (1)
- Show fake images from Generator → should output "fake" (0)
- Update Discriminator weights to improve classification
2. Train Generator
- Generate fake images
- Try to fool Discriminator into saying "real"
- Update Generator weights to produce more realistic images
┌─────────────────────────────────────────────────────────┐
│ Training Loop │
├─────────────────────────────────────────────────────────┤
│ For each batch: │
│ 1. Train Discriminator: │
│ - Real images → D → should be 1 │
│ - Fake images → D → should be 0 │
│ │
│ 2. Train Generator: │
│ - Generate fake images │
│ - Fake images → D → want it to be 1 │
│ - Update G to fool D better │
└─────────────────────────────────────────────────────────┘
Loss Functions in GAN
| Loss | Purpose | Used By |
|---|---|---|
| Adversarial loss (BCE/BCEwithLogits) | Real vs fake classification | Both G and D |
| L1 loss | Pixel-wise difference from target | Generator only |
For image-to-image tasks, the Generator's total loss often combines both:
- Adversarial loss: Encourages realistic-looking outputs
- L1 loss: Encourages outputs close to ground truth
The L1 loss is typically weighted heavily (e.g., ×100) to ensure the output matches the target while adversarial loss adds realistic details.
Train-Test Split
- Before training any machine learning model, we split the data into two parts:
| Dataset | Purpose | Typical Ratio |
|---|---|---|
| Training set | Used to train the model (update weights) | 80% |
| Test set | Used to evaluate performance on unseen data | 20% |
Why Split?
- Prevent overfitting: If we evaluate on the same data we trained on, the model might just "memorize" the training data instead of learning general patterns.
- Measure generalization: The test set simulates real-world usage where the model sees new, unseen data.
All Data (100 images)
│
├──▶ Training Set (80 images) ──▶ Used during training
│
└──▶ Test Set (20 images) ──▶ Never seen during training
Used only for evaluation
Summary
Simple MNIST GAN Pseudo-code
Below is a simplified pseudo-code showing the structure and flow of a GAN for generating MNIST digits:
# ============================================
# 1. Define Hyperparameters
# ============================================
latent_dim = 64 # Size of random noise input to Generator
hidden_dim = 256 # Number of neurons in hidden layers
image_dim = 28 * 28 # MNIST image size (784 pixels)
batch_size = 64
epochs = 50
learning_rate = 0.0002
# ============================================
# 2. Define Generator Network
# ============================================
class Generator:
# Architecture: noise → hidden layers → image
# Input: random noise vector (size: latent_dim)
# Output: fake image (size: image_dim)
def __init__(self):
# Layer 1: latent_dim → hidden_dim, then ReLU activation
# Layer 2: hidden_dim → hidden_dim, then ReLU activation
# Layer 3: hidden_dim → image_dim, then Tanh activation
# Tanh outputs values in range [-1, 1]
pass
def forward(self, z):
# z: random noise
# returns: generated fake image
pass
# ============================================
# 3. Define Discriminator Network
# ============================================
class Discriminator:
# Architecture: image → hidden layers → real/fake score
# Input: image (size: image_dim)
# Output: single value (probability of being real)
def __init__(self):
# Layer 1: image_dim → hidden_dim, then LeakyReLU activation
# Layer 2: hidden_dim → hidden_dim, then LeakyReLU activation
# Layer 3: hidden_dim → 1 (single output)
pass
def forward(self, x):
# x: input image (real or fake)
# returns: score indicating real (1) or fake (0)
pass
# ============================================
# 4. Initialize Models and Optimizers
# ============================================
generator = Generator()
discriminator = Discriminator()
# Loss function: Binary Cross Entropy (BCE)
# Optimizers: Adam optimizer for both G and D
# ============================================
# 5. Load MNIST Dataset
# ============================================
# Load 60,000 training images of handwritten digits
# Normalize pixel values to range [-1, 1]
# Create batches of size batch_size
# ============================================
# 6. Training Loop
# ============================================
for epoch in range(epochs):
for real_images in dataloader:
# ----- Step A: Train Discriminator -----
# Goal: D should output 1 for real, 0 for fake
# A1. Feed real images to D
d_output_real = discriminator(real_images)
loss_real = BCE(d_output_real, labels=1) # Should be 1
# A2. Generate fake images and feed to D
noise = random_normal(size=latent_dim)
fake_images = generator(noise)
d_output_fake = discriminator(fake_images)
loss_fake = BCE(d_output_fake, labels=0) # Should be 0
# A3. Update D weights
loss_d = loss_real + loss_fake
update_weights(discriminator, loss_d)
# ----- Step B: Train Generator -----
# Goal: G should fool D into outputting 1 for fake images
# B1. Generate new fake images
noise = random_normal(size=latent_dim)
fake_images = generator(noise)
# B2. Feed fake images to D
d_output = discriminator(fake_images)
loss_g = BCE(d_output, labels=1) # G wants D to say 1 (real)
# B3. Update G weights
update_weights(generator, loss_g)
print(f"Epoch {epoch}: D_loss={loss_d}, G_loss={loss_g}")
# ============================================
# 7. Generate New Images (After Training)
# ============================================
# noise = random_normal(size=latent_dim)
# new_image = generator(noise)
# The generated image should look like a handwritten digit!
Key points:
- Generator: Transforms random noise into fake images
- Discriminator: Learns to distinguish real images from fake ones
- Adversarial training: D and G compete - as D gets better at detecting fakes, G gets better at creating them
- Result: After training, G can generate realistic digit images from any random noise input