In this lecture, we will learn the basics of the neural network (NN).
Perceptron
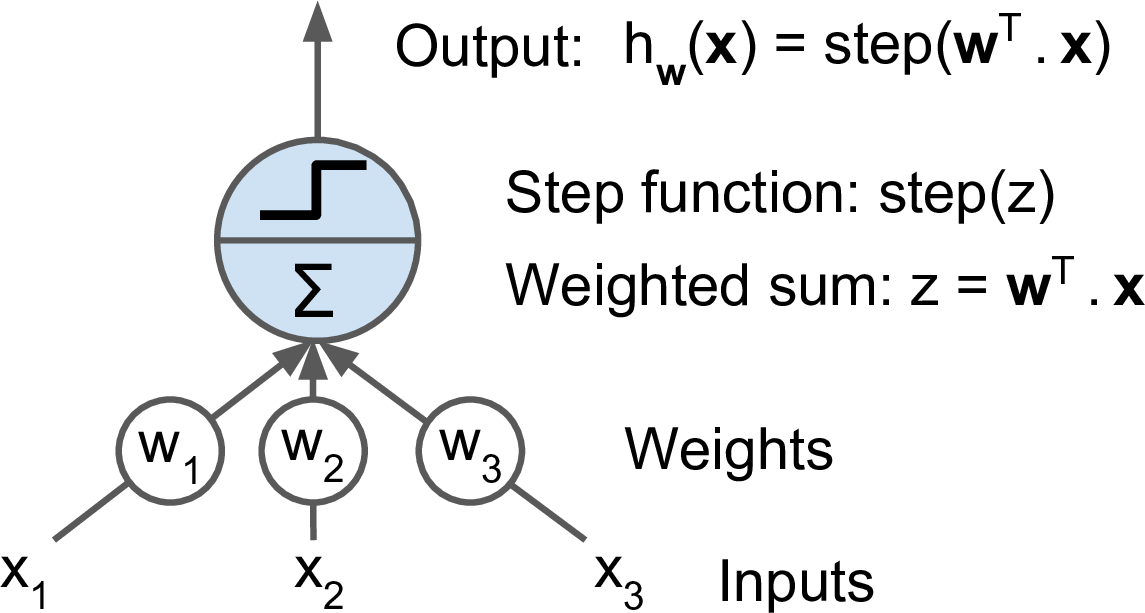
The perceptron is one of the simplest artificial neural network (ANN) archtechtures.
It is based on a artificial neuron called a linear threshold unit (LTU): the inputs and output are numbers and each input connection is associated with a weight w.
The LTU computes a weighted sum of its inputs (z=w1x1+w2x2+⋯+wnxn=wT⋅x), then applies a step function to sum and outputs the result: hw(x)=step(z)=step(wT⋅x).
A single LTU can be used for simple linear binary classification. It computes a linear combination of the inputs and if the result exceeds a threshold. Otherwise it outputs the positive class or else outputs the negative class.
For example, you can use a single LTU to classify iris flowers based on the petal length and width. Training an LTU means finding the right values for weights w0, w1, and w2.
Multi-layer perceptron
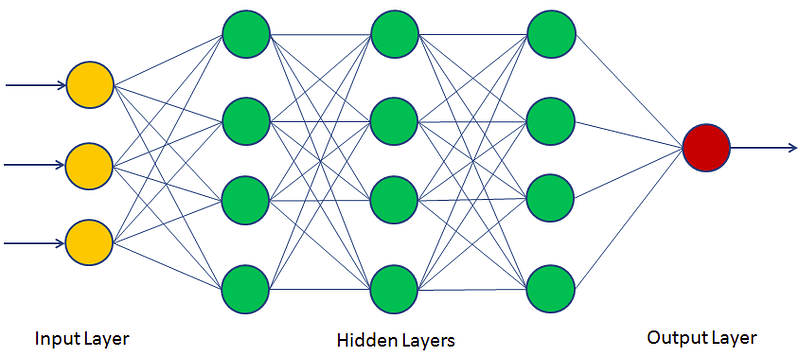
An multi-layer perceptron (MLP) typically has a following architechture: one (passthrough) input layer, one or more layers of LTUs (called hidden layers), and one final layer of the LTUs (called the output layer).
Every layer except the output layer includes a bias neuron and is fully connected to the next layer. When an ANN has two or more hidden layers, it is called a deep neutral network.
Backpropagation
For many years, researchers struggled to find a way to train MLPs, without success. But in 1986, D. E. Rumelhart et al. published a groundbreaking article introducing the backpropagation training algorithm.
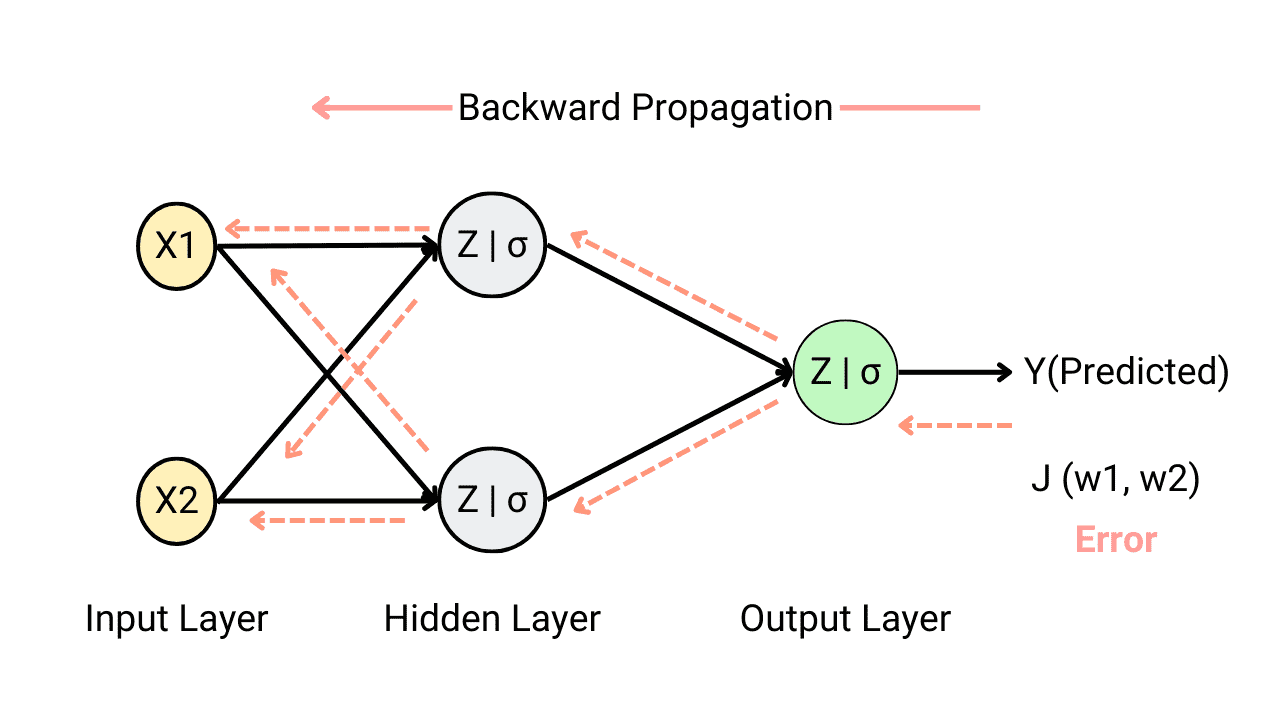
For each training instance, the algorithm feeds it to the network and coumputes the output of every neuron in each consective layer.
Then it measures the network's output error (i.e. the difference between the desired output and the actual output of the network). The error is measured by the loss function.
It computes how much each neuron in the last hidden layer contributed to the output. Similarly, contributions to the output from neurons in the hidden layer can be measured.
This reverse pass efficiently measures the error gradient across all the connection weights in the network by propagating the error gradient backward in the network.
Let's make this even shorter: for each training sample, the backpropagation algorithm first makes a prediction (forward pass), measures the error, then goes through each layer in reverse to measure the error contribution from each connection (reverse pass), and finally slightly adjust the connection weights to reduce the error (gradient descent step).
Activation function
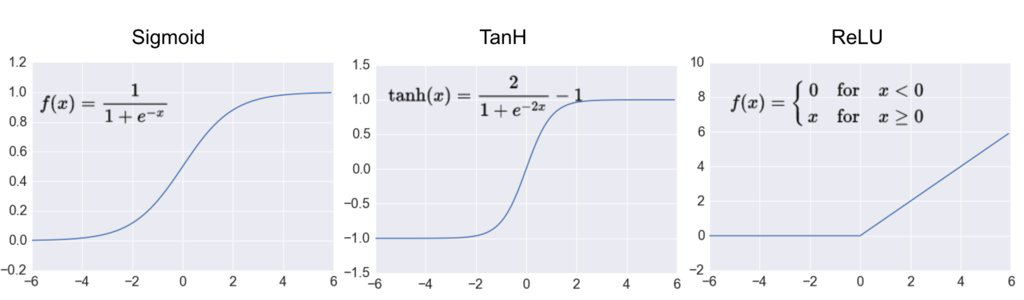
In order for the backpropagation to work properly, the authors made a key change to the MLP's archtecture: they replaced the step function with the sigmoid function, σ(z)=1/(1+exp(−z)).
This was an important change, because the step function contains only flat segments, so there is no gradient to work with. However, the sigmoid function has a well-defined nonzero derivative everywhere, allowing gradient descent to make some progress at every step.
The backpropagation algorithm may be used with other activation functions, instead of the sigmoid function.
Two popular activation functions are:
The hyperbolic tangent function (tanh)
Just like the sigmoid function, tanh(z)=2σ(2z)−1 is S-shaped, continuous and differentiable function. However, its output value ranges from -1 to 1, instead of 0 to 1 in the sigmoid function. This tends to make each layer's output more normalized (i.e. centered around 0) at the beginning of training, when tanh is used. This often helps speed-up the convergence.
The rectified linear unit (ReLU)
ReLU(z)=max(0,z) is continuous but unfortunately not differentiable at z=0 (the slope changes abruptly, which can make gradient descent bounce around). However, in practice, it works very well and has the advantage of being fast to compute. Most importantly, the fact that it does not have a maximum output value also helps reduce some issues during gradient descent.
Loss function
An MLP is often used for classification, with each output corresponding to a different binary class.
Let's consider the binary classification problem, in which the machine learning model tries to categolize the sample either into 0 or 1.
The classifier tries to calculate the probability for categolizing the sample data. Good classifier has lower loss function, and in binary classification problem the binary cross entropy (BCE) loss is often used.
Here, yi is the actual class label (e.g. 0 or 1) obtained from the labeled data. p(yi) is the probability of that class, calculated from the model. When p(yi) is close to yi, the BCE loss is small.